
Darsey Litzenberger
(formerly: Dwayne Litzenberger)
The Pearson product-moment correlation coefficient (PMCC) is a quantity between -1.0 and 1.0 that estimates the strength of the linear relationship between two random variables.
The PMCC in its usual form is somewhat cumbersome to calculate. Using simple algebra, I have rearranged it to form an expression that should have better numerical stability and require fewer calculations.
Disclaimer: This page is primarily for my own reference. I am a programmer without formal training in statistics, and I don't even feel like I know what I'm doing. There are probably a ton of assumptions that I am unwittingly making, I am almost certainly misusing the terminology, and I could simply be flat-out wrong here. My apologies to statisticians and to people like Zed Shaw who have a far greater understanding of this stuff than I do. If you blindly trust this page while building something important---even after what I just told you---then the blame is all yours. Use your brain. Don't believe everything you read. This is not even a very interesting article: It's mostly just algebra. Don't read this page; It's a waste of your time.
On a more serious note: In an attempt to make this article less cringe-worthy, I made an effort to find the original peer-reviewed article(s) where the Pearson correlation might be defined precisely, but nothing I read cited primary references (MathWorld just cited textbooks, for example) and I don't have the money to buy expensive journal articles for every little web page I write. After searching for most of a day, I finally gave up in frustration and decided to post this article anyway, flaws and all. If this article makes you cringe, please consider doing something to advance the principle of open access.
Imagine we have two populations X and Y. Then ρX,Y represents the product-moment coefficient of correlation between them.
Various websites and textbooks describe the correlation coefficient in several equivalent ways:
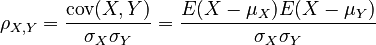
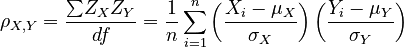
We often can't work with populations directly, so we can't determine the exact value of ρX,Y. However, we can estimate it by selecting a random sample of (x,y) pairs. This estimate is often labelled r. Since we can use the same formula for either case, I call the general formula PMCC(X,Y).
Let PMCC(X,Y) be the Pearson product-moment correlation coefficient of two n-dimensional vectors X = {X1,X2,...,Xn} and Y = {Y1,Y2,...,Yn}.
Let 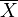 and
and 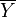 be the arithmetic
means of the elements in X and Y, respectively.
be the arithmetic
means of the elements in X and Y, respectively.
Let sX and sY be the standard deviations of X and Y, respectively.
Then, the following relations apply. Note how we define N in order to avoid having to do two separate analyses for population and sample data:
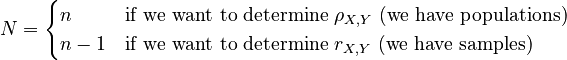 |
||
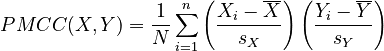 |
||
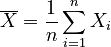 |
, | 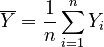 |
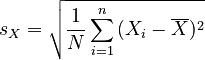 |
, | 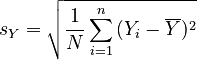 |
Given the vectors X and Y, there are a few things we can calculate right away:
| The sums of all the elements in each vector: | ||
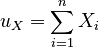 |
, | 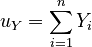 |
| The squares of the sums of all the elements in each vector: | ||
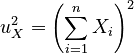 |
, | 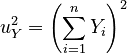 |
| The sums of the squares of all the elements in each vector: | ||
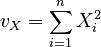 |
, | 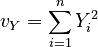 |
| The sum of the products of the corresponding elements from each vector: | ||
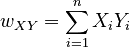 |
||
We can now reduce the arithmetic means in terms of our previous calculations:
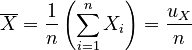
|
, |
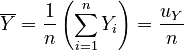
|
To simplify the standard deviations, we first reduce the squares of the deviations:
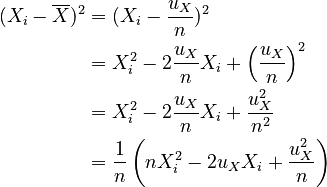
Then, we simplify the variance:
![\begin{align}
s_X^2 &= \frac{1}{N} \sum_{i=1}^n (X_i - \overline{X})^2 \\
&= \frac{1}{N} \sum_{i=1}^n \left[ \frac{1}{n} \left( n X_i^2 - 2 u_X X_i + \frac{u_X^2}{n} \right) \right] \\
&= \frac{1}{N} \frac{1}{n} \sum_{i=1}^n \left( n X_i^2 - 2 u_X X_i + \frac{u_X^2}{n} \right) \\
&= \frac{1}{N} \frac{1}{n} \left[ \left( \sum_{i=1}^n n X_i^2 \right) - \left( \sum_{i=1}^n 2 u_X X_i \right) + \left( \sum_{i=1}^n \frac{u_X^2}{n} \right) \right] \\
&= \frac{1}{N} \frac{1}{n} \left[ (n) \left( \sum_{i=1}^n X_i^2 \right) - (2 u_X) \left( \sum_{i=1}^n X_i \right) + \left( \frac{u_X^2}{n} \right) \left( \sum_{i=1}^n 1 \right) \right] \\
&= \frac{1}{N} \frac{1}{n} \left[ (n) (v_X) - (2 u_X) (u_X) + \left( \frac{u_X^2}{n} \right) (n) \right] \\
&= \frac{1}{N} \frac{1}{n} \left( n v_X - 2 u_X^2 + u_X^2 \right) \\
&= \frac{1}{n N} \left( n v_X - u_X^2 \right)
\end{align}](../../../generated/texvc/a2621ea6aa40ea6dd91e88d51ce56411.png)
Therefore, the reduced standard deviations are:
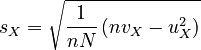 |
, | 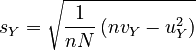 |
Recall the PMCC formula:
|
and the results we derived:
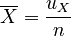
|
, |
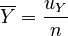
|
|
, | |
Performing substitution, we get:
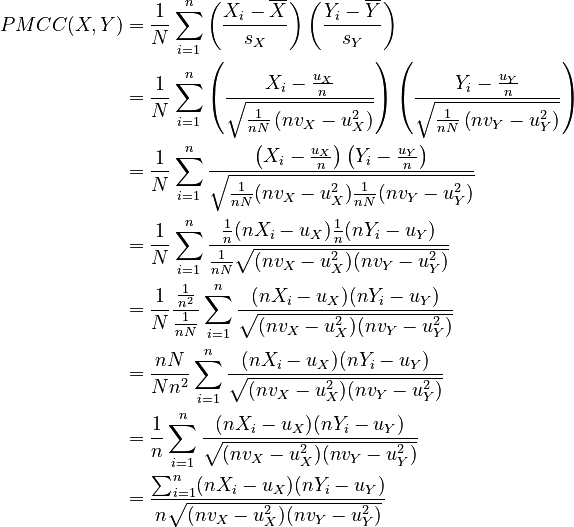
Notice how the formula no longer depends on whether the data is from a population or from a sample.
Let's reduce the summation from the previous section:
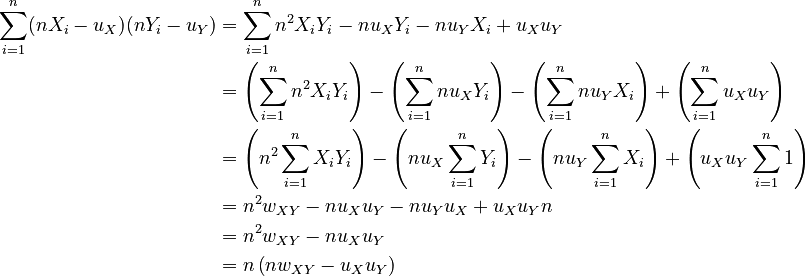
Substituting, we get:
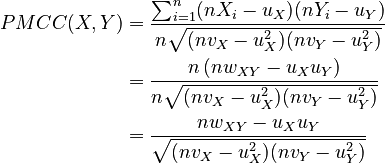
Given two populations or samples X = {X1,X2,...,Xn} and Y = {Y1,Y2,...,Yn} (and subject to some assumptions about the distributions of the data), the Pearson product-moment correlation coefficient of the two is given by:
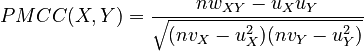
where the following variables are defined:
|
, | |
|
, | |
|
, | |
|
||
Alternatively, we can use the expanded form (which is obtained by applying the previous substitutions):
![PMCC(X,Y) =
\frac{
n \left( \sum_{i=1}^n X_i Y_i \right) - \left( \sum_{i=1}^n X_i \right) \left( \sum_{i=1}^n Y_i \right)
}{
\sqrt{ \left[ n \left( \sum_{i=1}^n X_i^2 \right) - \left( \sum_{i=1}^n X_i \right)^2 \right] \left[ n \left( \sum_{i=1}^n Y_i^2 \right) - \left( \sum_{i=1}^n Y_i \right)^2 \right] }
}](../../../generated/texvc/1ee430e03ac3699bd045f795c4c8a815.png)
When computing the sum of several floating-point values that vary widely, you can obtain a better approximation (less round-off error) by sorting the terms in ascending order before adding them together. That way, the smaller numbers will be added together before being added to larger numbers, rather than being immediately truncated. The Wikipedia article on numerical stability has a bit more information about this.